
資料分析是企業下一個待開發的核心競爭力,尤其在 AI 時代,如何高效、可靠地提供大數據作為模型訓練的燃料,成為 IT 架構師的首要難題。
在生成式 AI 時代,資料治理的挑戰變得更加複雜,AWS 的研究顯示,39% 的受訪者將資料清理、整合和儲存視為使用生成式 AI 的障礙,49% 正在專注於資料質量,46% 則關注資料整合,這凸顯了建立強大資料治理架構的重要性,以支援 AI 模型的訓練和應用。
由以上資料可看出,企業普遍面臨的挑戰是,雖然數據量龐大,但企業寶貴資料卻分散在各處,形成難以駕馭的「資料孤島」,這種資料分散的狀態,直接阻礙了資料整合,使得企業無法從單一、可信賴的來源進行大數據分析與價值轉換。
要將這些數據轉化為決策的「有效資料」,企業必須專注於兩大策略:高效的資料遷移上雲,以及嚴謹的企業資料治理。本文將深入帶您了解資料整合方法論,為您的資料治理架構提供具體藍圖。
3 種主要資料整合方法
資料整合的目標很簡單:將分散在企業各處的原始資料,經過標準化與清洗後,匯聚到統一的分析環境中,以便企業能快速運用,以下整理 3 種資料整合方式,並協助你依照資料特性選擇方法:
傳統資料批次整合(ETL)
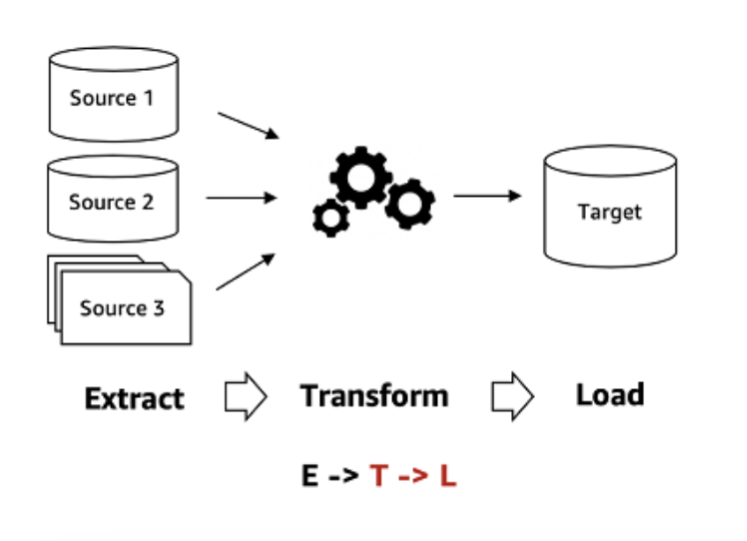
這是歷史比較悠久的經典資料整合模式,在這個流程中,使用者需要先在來源系統中擷取資料,並依照自身業務需求對資料進行「手動定義」清洗,將資料格式統一,最後將這些已經轉化的、結構化資料載入到目標系統,如企業資料倉儲(Data Warehouse)。
雲端運算資料整合(ELT)
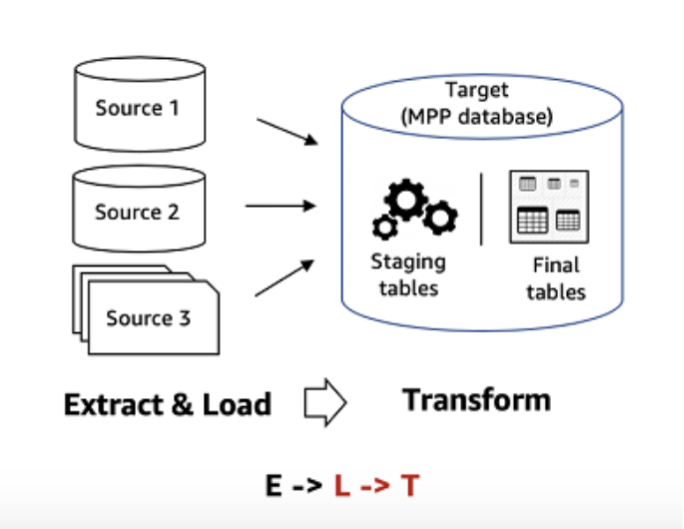
是雲端運算環境資料整合方法,它與 ETL 最大的區別在於順序的切換,在 ELT 流程中,原始資料會被直接、快速地載入到雲端儲存系統(例如 Amazon S3 或資料湖)中,無需先行清洗,適合處理非結構化資料,支援更快的即時資料整合能力。
資料複製
將來源資料即時複製,確保資料在不同系統間保持一制性,此方法可實現資料的零時差或近乎零時差同步,有助於分散查詢負載,提升系統的高可用性。此技術常應用於需要零停機時間的資料庫遷移,如將本地機房的交易資料庫同步上雲,像是金融業需要將核心交易資料即時同步至風險監控系統以滿足法規要求的場景。
資料整合方法評估
面對上述三種主要的資料整合模式,雲端架構師和 IT 決策者的下一步是針對企業的業務需求和雲端架構進行評估。
這是一個綜合考量資料治理、預算與未來擴展性的策略性決策。在規劃您的雲端資料策略時,請務必深入評估以下三個關鍵因素:
資料數量
當企業的資料量從 GB、TB,甚至成長到 PB 級規模時,傳統的 ETL(Extract, Transform, Load)流程往往會面臨效能瓶頸。這是因為在載入前需先進行大量資料清洗與格式轉換,不僅耗時,也會造成系統負載過重,難以即時支援分析需求。
相對地,若企業的資料呈現指數型成長,且包含大量非結構化資料(例如客戶點擊紀錄、社群互動內容、IoT 裝置資料等),則更適合採用 ELT 架構。此模式能將原始資料直接載入高彈性、低成本的資料湖(如 Amazon S3),再依分析需求進行彈性轉換與處理。
透過這種方式,企業不僅能降低前期的資料處理壓力,也能加快資料進入分析階段的速度,讓業務決策能更快掌握最新趨勢,真正發揮資料的價值。
即時性要求
當企業的應用場景需要在毫秒之間做出反應,例如金融風險監控、即時廣告競價或線上交易異常偵測等,傳統的批次處理方式將無法滿足需求。
在這類高即時性場景中,建議採用資料複製技術,確保資料在產生的同時就能被同步與分析,此方法可讓系統隨時掌握最新資訊,實現真正的即時決策,協助企業在關鍵時刻即刻應對風險與商機。
轉換的複雜度
若企業的資料在載入前需要經過大量格式標準化、清理、或去識別化處理,採用傳統的 ETL 流程會更有效率,能在進入目的端前就確保資料品質與一致性。
然而,若資料轉換邏輯變動頻繁,或業務團隊需要在分析階段靈活探索原始資料,則 ELT架構更具優勢,此模式讓資料科學家與分析師可直接操作原始資料集,快速調整轉換邏輯,縮短從資料到洞察的時間,提升整體分析靈活度。
AWS 資料整合服務
當企業確立資料整合策略後,接下來的重點是選擇合適的雲端服務實踐方案。AWS 提供多元工具,可協助企業依照不同資料類型與整合需求,快速、安全地完成資料流動與分析。
跨平台資料整合工具:AWS Glue
AWS Glue 是 AWS 提供的無伺服器 ELT 服務,也是實現現代化雲端資料整合的核心工具,可處理大量跨系統、跨格式的資料,降低維運與開發負擔。
在資料處理流程中,AWS Glue 能自動生成以 Python(Spark)或 Scala 撰寫的轉換程式碼,用於資料清洗、轉換與整合,協助企業快速建構可重複使用的資料管線。
同時,AWS Glue Data Catalog 則扮演企業的「資料目錄中樞」,自動掃描並記錄各資料來源的結構與位置,可連線超過 100 個不同的資料來源,無論資料儲存在 Amazon S3、Amazon Redshift,或 Amazon RDS,皆可透過統一的入口進行查詢與管理,強化了資料可見性與可用性,也為後續的資料治理與分析奠定基礎。
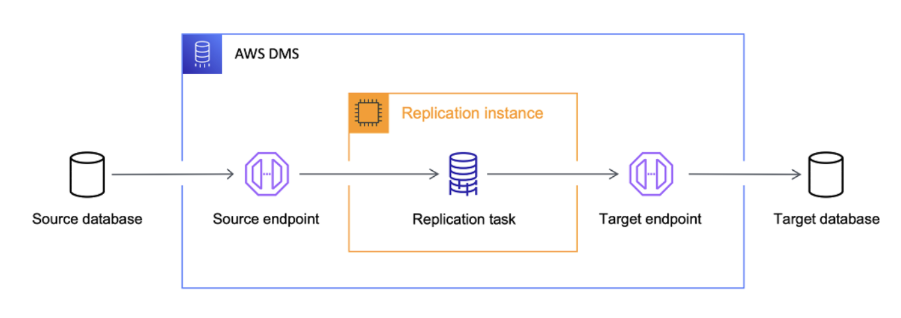
資料複製:AWS DMS (AWS Database Migration Service)
為資料遷移與複製設計的核心服務,能協助企業輕鬆將資料庫從本地機房或其他雲端環境,平順遷移至 AWS。它支援超過 20 種主流資料庫來源與目標,包括 Oracle、MySQL、PostgreSQL、Amazon Aurora 等,提供高度相容與彈性的遷移能力。
在實務應用上,AWS DMS 特別適合進行「零停機時間」的異構或同構資料庫遷移,例如從 Oracle 遷移至 Amazon Aurora,透過持續資料複寫(Change Data Capture, CDC)機制,AWS DMS 能在遷移過程中即時同步更新變動資料,確保系統持續運作、業務不中斷。
這項能力讓企業能更安全地完成雲端轉型,同時兼顧穩定性與可用性,為後續的資料整合與分析奠定穩固基礎。
資料湖查詢:Amazon S3 與分析服務
在資料湖架構中,資料雖集中儲存在 Amazon S3,但真正發揮價值的關鍵在於「如何查詢與分析」,為了讓企業能直接在資料湖中進行靈活分析,Amazon Redshift 與 Amazon Athena 提供了兩種互補的查詢方式。
Amazon Redshift 是全託管的雲端資料倉儲服務,支援與 S3 資料湖整合,可讓使用者在不移動資料的情況下,直接對資料湖中的結構化資料執行高效查詢,能以倉儲級效能,分析跨多個來源的資料集,適合長期報表、商業智慧與趨勢分析。
Amazon Athena 則以立即查詢(ad-hoc query)為核心,讓使用者使用標準 SQL 直接查詢儲存在 S3 的原始資料,Athena 無需事前建立資料庫或載入流程,非常適合進行快速探索、資料檢視或臨時分析,協助團隊即時獲取洞察。
資料上雲與治理是一項複雜工程,需要對 AWS 服務 有深入理解與豐富實戰經驗,若您的企業正面臨資料整合或資料遷移挑戰,或需要專業的企業資料治理服務導入建議,CKmates 的專業顧問團隊可以提供完整解決方案,協助您將資料價值最大化。
